TL;DR
- AH2AC2 is a benchmark for evaluating how well AI agents can coordinate with humans in the complex, partially observable, cooperative game Hanabi, especially when access to human data is limited.
- We provide the first open-source dataset of human gameplay in Hanabi, consisting of 1,858 two-player and 1,221 three-player games.
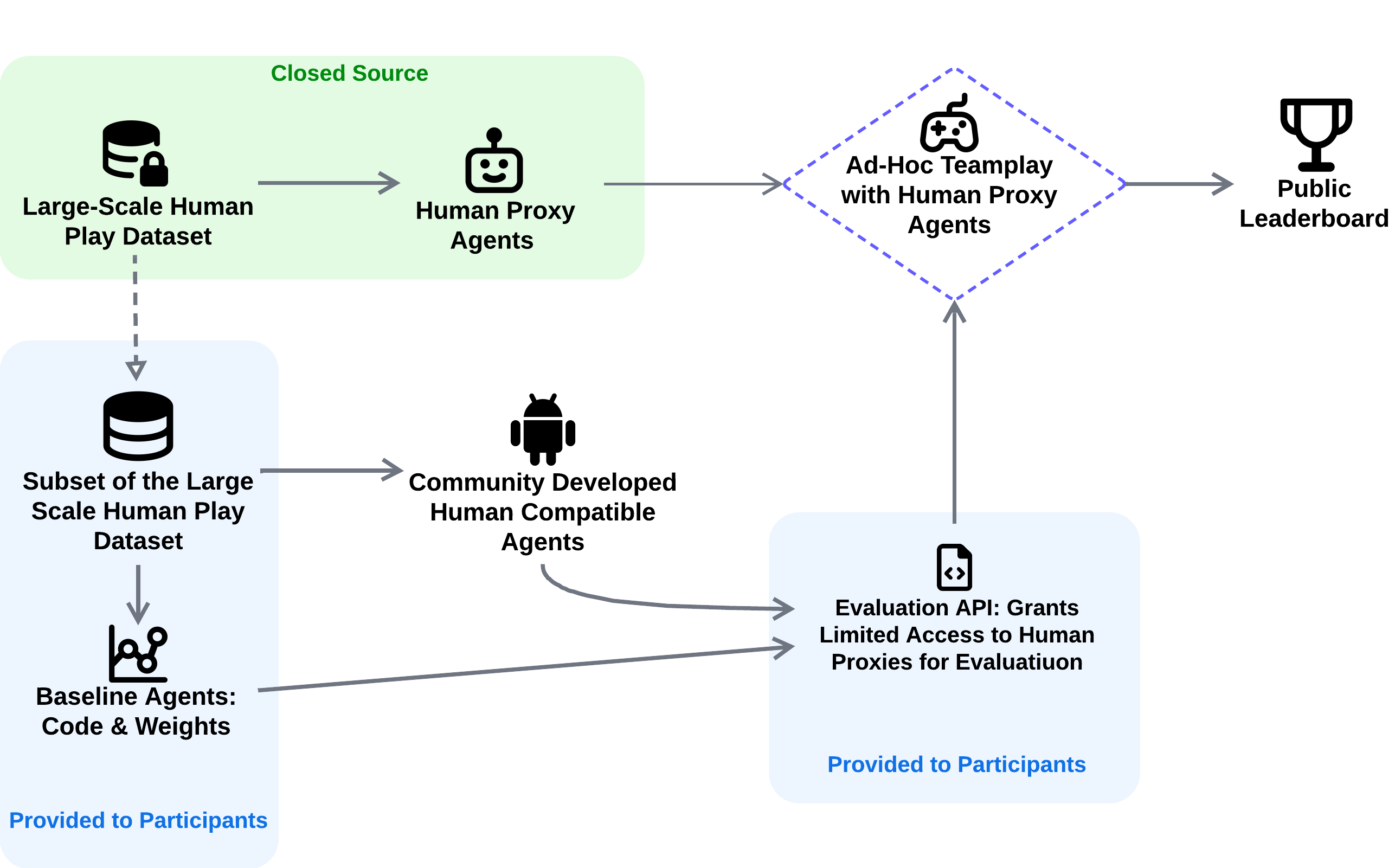
- We have developed high-performing human proxy agents, trained on a massive dataset (over 100k games), to serve as standardized evaluation partners. These are kept behind an API to ensure evaluation integrity.
- Our initial baseline evaluations show that current methods struggle to effectively use limited human data for coordination, highlighting a significant research gap.
- We invite the research community to participate, test their methods, and help advance human-AI coordination!
- Our research paper introducing the Ad-Hoc Human-AI Coordination Challenge (AH2AC2) has been accepted to ICML 🎉!
Our key contributions include:
- 📊 The first open-source Hanabi human gameplay dataset.
- 🤖 Robust human proxy agents for evaluation, developed using a combination of behavioural cloning and regularised reinforcement learning on a large private dataset.
- 🔧 An evaluation protocol with an API for accessing the proxy agents and a public leaderboard to track progress.
- 📈 A set of diverse baselines to kickstart research and provide initial performance benchmarks.
Ad-Hoc Human-AI Coordination Challenge (AH2AC2)
Ad-Hoc Human-AI Coordination Benchmark
As AI becomes more integrated into our daily lives, the ability for AI agents to effectively coordinate with humans is crucial. Traditional AI training methods, like self-play, often lead to agents that are good at playing with themselves but struggle to adapt to human partners.
Hanabi serves as an excellent testbed for human-AI coordination due to its emphasis on imperfect information, limited communication, theory of mind, and the need for coordinated action to achieve a shared goal. While previous research has explored Hanabi, a lack of standardised benchmarks and open datasets has hindered progress.
To address these challenges, we introduce the Ad-Hoc Human-AI Coordination Challenge (AH2AC2). AH2AC2 provides a standardized framework for evaluating AI agents' ability to coordinate with human-like partners in Hanabi, particularly focusing on scenarios where only a small amount of human gameplay data is available for training. The goal is to foster the development of AI agents that can effectively collaborate with humans.

Dataset
A core component of AH2AC2 is the release of the first open-source dataset of human Hanabi gameplay. This dataset contains 1,858 two-player games and 1,221 three-player games, collected from the hanab.live platform.
Open-Sourced Data Statistics:
| Setting | Metric | Min | Max | Avg | Median | Std |
|---|---|---|---|---|---|---|
| 1,858 Two-Player Games | Scores | 13 | 25 | 23.37 | 24 | 1.86 |
| Game Lengths | 52 | 76 | 65.45 | 66 | 3.35 | |
| 1,221 Three-Player Games | Scores | 14 | 25 | 23.25 | 24 | 1.91 |
| Game Lengths | 45 | 67 | 57.86 | 58 | 3.38 |
This open-sourced data is a subset of a much larger dataset (over 100,000 two-player games and over 46,000 three-player games) that we used to train our human proxy agents. By releasing only a limited dataset, we aim to encourage research into data-efficient methods for human-AI coordination.
Data Access: Participants can access the open-sourced games to develop their agents. Details on accessing the data can be found on the challenge website (placeholder link).
Evaluation
The AH2AC2 evaluation has two main parts:
- Coordination with Human Proxies: Participants develop agents that are then evaluated by playing 1,000 games with our human proxy agents. These proxies are trained on our large, private dataset and are designed to exhibit human-like playstyles.
- Human Action Prediction (Optional): Agents are evaluated on their ability to predict human actions in an unseen set of human-played games, measured by cross-entropy loss.
To ensure fairness and prevent overfitting to the proxy agents, access to them is controlled.
Results
We evaluated several baseline methods within the AH2AC2 framework. These include:
- IPPO (Independent Proximal Policy Optimization): Trained via self-play, no human data.
- BC (Behavioral Cloning): Trained solely on the open-sourced human data.
- HDR-IPPO (Human-Data-Regularized IPPO): Builds on BC by incorporating regularized reinforcement learning.
- BR-BC (Best Response to BC): Trains an agent to best respond to a fixed BC policy.
- OBL (Off-Belief Learning): SOTA zero-shot coordination method (no human data).
- OP (Other-Play): A zero-shot coordination method.
- FCP (Fictitious Co-Play): A population-based training method.
- DeepSeek-R1: A strong reasoning LLM evaluated without Hanabi-specific fine-tuning, using two prompting variants: basic game state description and enhanced with H-conventions.
Initial AH2AC2 Leaderboard:
Two-Player Results
| Method | Mean | Median | CE |
|---|---|---|---|
| OBL (L4) | 21.04 | 22 | 1.33 |
| BR-BC | 19.41 | 20 | 10.82 |
| FCP | 14.01 | 16 | 3.52 |
| OP | 13.91 | 19 | 7.81 |
| HDR-IPPO | 12.76 | 15 | 0.96 |
| IPPO | 10.16 | 14 | 12.60 |
| DeepSeek-R1 H-Group | 9.91 | 0 | - |
| DeepSeek-R1 | 5.43 | 0 | - |
| BC | 2.12 | 0 | 0.86 |
| Human Proxies † | 22.76 | 23 | 0.54 |
| BR-BC* † | 22.59 | 23 | 5.00 |
Three-Player Results
| Method | Mean | Median | CE |
|---|---|---|---|
| DeepSeek-R1 H-Group | 14.62 | 18 | - |
| DeepSeek-R1 | 14.38 | 18 | - |
| HDR-IPPO | 14.03 | 16 | 0.80 |
| OP | 12.87 | 18 | 6.40 |
| BR-BC | 11.89 | 12 | 29.89 |
| FCP | 11.55 | 6.0 | 5.97 |
| IPPO | 6.34 | 0 | 8.60 |
| BC | 3.31 | 0 | 0.70 |
| Human Proxies † | 20.86 | 21 | 0.62 |
| BR-BC* † | 18.80 | 19 | 7.53 |
† Not constrained by challenge limits (uses full dataset for BC in BR-BC*), acts as a golden standard. We report average performance over two human proxies.
🔍 Our results underscore a critical research gap: current methods are not yet sufficient to effectively integrate small human datasets to significantly enhance coordination capabilities. While DeepSeek-R1 demonstrates foundational capability, particularly in three-player settings where it outperforms traditional baselines, significant improvements are still needed to match human-level coordination.
LLM Evaluation Insights: We evaluated DeepSeek-R1 with two prompting approaches: basic game state description and enhanced prompts including H-conventions. While providing H-conventions substantially improved performance in two-player games (5.43 vs 9.91), the LLM still significantly underperforms compared to OBL. Interestingly, in three-player settings, DeepSeek-R1 achieved the highest scores among all baselines, suggesting some inherent coordination capabilities.
Evaluation API
To participate and ensure a fair evaluation process, we host the human proxy agents and provide access through a dedicated Evaluation API. Participants must register to receive a private key. This key allows a one-time evaluation run (1,000 games) against our human proxies. The API ensures that agents only receive local observations, maintaining the partial observability inherent to Hanabi. After the evaluation, results are automatically published on the challenge leaderboard.
What Now?
We believe AH2AC2 is a significant step towards advancing research in human-AI coordination. We invite you to get involved!
- 📄 Read the paper: arXiv
- 📊 Get the data we open source: Huggingface
- 🏆 See the up-to-date leaderboard: Official Website
- ✍️ Register your interest for participation: Official Website
- 🔧 Check out the API docs for evaluating your methods: Docs