Introduction - What is UED?
Unsupervised Environment Design (UED) is a paradigm where an adversary generates environment configurations for a reinforcement learning (RL) agent to learn on. This adversary generally chooses levels in order to maximise some objective function; one common objective—and the one we deal with in this work—is to maximise the agent's regret, which is the difference between the performance of the optimal policy on that level and that of the agent.

In other words, regret measures how much better a particular agent could perform on a particular level. Empirically, training on these regret-maximising levels has been shown to improve generalisation to out-of-distribution levels in challenging domains
Consider the following example, where an adversary can sample T-mazes and normal mazes. In the T-mazes, the reward for reaching the goal is $1.0$ and $-1.0$ for failing. The reward for the mazes is $0.9$ for reaching the goal, and zero otherwise. Each T-maze looks identical from the agent's perspective, and its minimax regret behaviour is to go left or right with 50% probability. See this section for a derivation of this solution.
There are two policies in the following video. Both of these have the same worst-case regret (1.0) in the T-mazes, achieved by randomly choosing left or right. However, policy 1 is effectively random in the maze, whereas policy 2 actually goes to the goal. Both of these are minimax regret policies, but policy 2 is clearly better. Using standard UED cannot guarantee that we won't get stuck with policy 1, even though policy 2 is possible! In general, there may be multiple minimax regret policies, and we aren't guaranteed to get the "best" one when using minimax regret.
The rest of this post describes this problem in more detail, proposes a solution and demonstrates the effectiveness of this solution in a variety of environments. See the full paper for more details and proofs of theoretical results.
Background
RL & UPOMDPs
We consider an underspecified partially-observable Markov decison process (UPOMDP)Unsupervised Environment Design
Unsupervised Environment Design (UED) is posed as a two-player game, where an adversary $\Lambda$ selects levels $\theta$ for an agent $\pi$ to train onTwo-Player Game Formulation of UED
In UED, it can be helpful to think of the problem as a two-player zero sum matrix game. Concretely, the adversary's strategy set is $\Theta$, the set of all levels. The agent's strategy set is $\Pi$, the set of all policies. For a particular $\langle \theta, \pi \rangle$, the payoff (which the adversary aims to maximise and the agent seeks to minimise) is the regret of $\pi$ on $\theta$: $\text{Regret}_\theta(\pi)$. The equilibrium of UED is when the adversary selects a level and the agent chooses a particular policy, such that neither can improve their payoff by only changing their strategy. We note that equilibria may consist of mixed strategies, i.e., probability distributions over the strategy set. In this way, the adversary can end up sampling a distribution of levels, and the policy can stochastically chooses behaviour.
As a concrete example, let's calculate the equilibrium in the T-Maze example. We do this by explicitly constructing the decision matrix for the T-mazes. The table on the left illustrates the reward for each action in each environment, whereas the right table shows the regret. UED treats this as the payoff matrix for a two-player zero-sum game, where the agent chooses a column, and the adversary chooses a row. Since this game is similar to matching pennies, the equilibrium is for the agent to choose left or right with 50% probability, and the adversary to choose each environment with 50% probability. This results in a worst-case regret of 1.0, which is the best we can do in this environment.
Move Left
Move Right
Goal on Left
+1
-1
Goal on Right
-1
+1
Move Left
Move Right
Goal on Left
0
2
Goal on Right
2
0
The Limits of Minimax Regret
To elucidate the issues with using minimax regret in isolation, we analyse the set of minimax regret policies $\pi^\star_\text{MMR}$. For any $\pi_\text{MMR}\in \Pi^\star_\text{MMR}$ and $\vartheta \in \Theta$, it trivially holds that:
However, it is unclear whether all policies in $\Pi^\star_\text{MMR}$ are equally desirable across all levels. In the worst case, the minimax-regret game will converge to an agent policy that only performs as well as this bound, even if further improvement is possible on other (non-minimax regret) levels. In addition, the adversary's distribution will not change at such Nash equilibria, by definition. Thus, at equilibrium the agent will not be presented with levels outside the support of $\Lambda$ and as such will not have the opportunity to improve further---despite the possible existence of other MMR policies with lower regret outside the support of $\Lambda$.
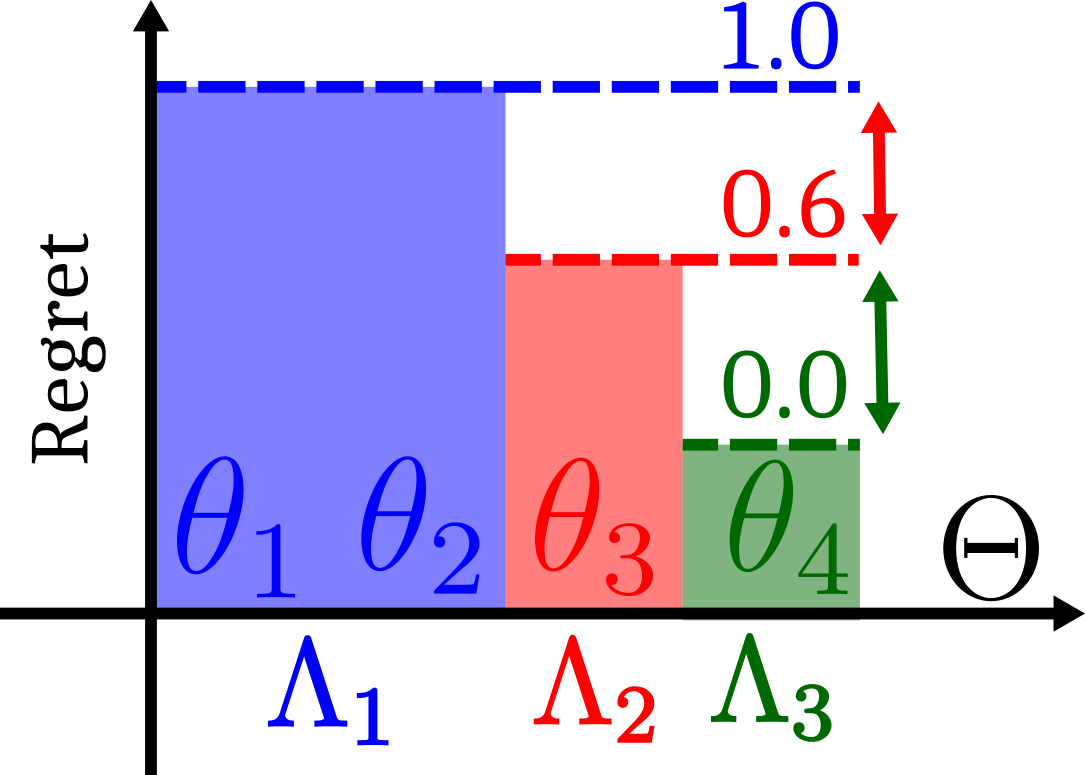
The following figure illustrates this problem: Minimax regret only guarantees that all levels have regret equal to or lower than the best worst-case regret, even if a lower regret is possible (e.g. on the right).


This observation demonstrates that minimax regret does not always correspond to learnability: there could exist UPOMDPs with high regret on a subset of levels on which an agent is optimal (given the partial observability constraints), and low regret on levels in which it can still improve. Our key insight is that optimising solely for minimax regret can result in the agent's learning to stop prematurely, preventing further improvement across levels outside the support of MMR levels. We summarise this regret stagnation problem of minimax regret as follows:
- The minimax regret game is indifferent to which MMR policy is achieved on convergence
- Upon convergence to a policy in $\Pi^\star_\text{MMR}$, no improvements occur on levels outside the support of $\Lambda$.
Refining Minimax Regret
Now, how do we fix this? Loosely, our idea is that we want to get a minimax regret policy and improve it. The improvement should be done in such a way that we do not lose minimax regret guarantees on the existing MMR levels. We can do this by restricting our new policy to act in exactly the same way as the MMR policy in all trajectories that can be seen using $\pi$ and $\Lambda$. We first define the notion of a realisable trajectory, which is necessary to understand the rest of this section.For a set $\Theta'$ and policy $\pi$, $\mathcal{T}_{\pi}(\Theta')$ denotes the set of all trajectories that are possible by following $\pi$ on any $\theta \in \Theta'$. We call a trajectory $\tau$ realisable under $\pi$ and $\Theta'$ iff $\tau \in \mathcal{T}_{\pi}(\Theta')$. I.e., $\mathcal{T}_{\pi}(\Theta')$ is the set of all trajectories that have nonzero probability given a set $\Theta'$ and a policy $\pi$.
Given a UPOMDP with level space $\Theta$, suppose we have some policy $\pi$ and some subset of levels $\Theta' \subseteq \Theta$. We introduce the refined minimax regret game under $\pi$ and $\Theta'$, a two-player zero-sum game between an agent and adversary where:
- the agent's strategy set is all policies of the form
\pi'(a | \tau) = \begin{cases} \pi(a | \tau) \text{ if } \tau \in \mathcal{T}_{\pi}(\Theta') \\ \bar{\pi}(a | \tau) \text{ otherwise}\end{cases}
where $\bar{\pi}$ is an arbitrary policy; - the adversary's strategy set is $\overline{\Theta} \dot = \Theta \setminus \Theta'$;
- the adversary's payoff is $\text{Regret}_\theta(\pi')$.
This refined game is quite powerful, and it allows us to fix a policy's behaviour over a set of levels, and improve its worst-case regret in non-highest-regret levels!
We next present a few important theoretical results regarding the refined game, and the proofs can be found in the full paper.
Suppose we have a UPOMDP with level space $\Theta$. Let $\pi$ be some policy and $\Theta' \subseteq \Theta$ be some subset of levels. Let $(\pi', \Lambda')$ denote a policy and adversary at Nash equilibrium for the refined minimax regret game under $\pi$ and $\Theta'$. Then, (a) for all $\theta \in \Theta'$, $\text{Regret}_\theta(\pi') = \text{Regret}_\theta(\pi))$; and (b) we have,
Let $\langle \pi_1$, $\Lambda_1 \rangle$ be in Nash equilibrium of the minimax regret game. Let $\langle \pi_i, \Lambda_i \rangle$ with $1 < i$ denote the Nash equilibrium solution to the refined minimax regret game under $\pi_{i-1}$ and $\Theta_i' = \bigcup_{j = 1}^{i-1} \text{Supp}(\Lambda_j)$.
Then, for all $i \geq 1$, (a) $\pi_{i}$ is minimax regret and (b) we have
In other words, iteratively refining a minimax regret policy (a) retains minimax regret guarantees; (b) monotonically improves worst-case regret on the set of levels not already sampled by any adversary; and (c) retains regret of previous refinements on previous adversaries.
Let $\langle \pi_1, \Lambda_1 \rangle$ be in Nash equilibrium of the minimax regret game. Let $\langle \pi_i, \Lambda_i \rangle$, $1 < i$ denote the solution to the refined game under $\pi_{i-1}$ and $\bigcup_{j = 1}^{i-1} \text{Supp}(\Lambda_j)$. Policy $\pi_j$ is a Bayesian level-perfect minimax regret policy if $\bigcup_{k=1}^{j} \text{Supp}(\Lambda_k) = \Theta$.
Algorithm
Now, all of this was quite abstract. So what does this actually do? Well, the core idea is that we want to always keep minimax regret guarantees. The way we do this is to fix the policy's behaviour on all trajectories realisable under an MMR policy and adversary. We then improve the policy's worst-case regret on all other levels by solving the refined game. We repeat this process until we have considered all levels.
To demonstrate the benefit of this solution concept, we develop a proof-of-concept algorithm that results in a BLP policy at convergence. We call this algorithm Refining Minimax Regret Distributions, or ReMiDi for short. This algorithm is a direct implementation of the solution concept above, and explicitly maintains a set of adversaries and policies. In practice, though, we only have one policy, and we restrict its updates to only occur on trajectories that are inconsistent with any previous adversary.

The following figures illustrate what applying our method does, iteratively filling in behaviour for all non-previously sampled levels.

Experiments
We perform several experiments in domains that exhibit irreducible regret and show that ReMiDi alleviates this problem.
Our experimental setup for the non-exact settings is as follows.
We compare against Robust PLR ($\text{PLR}^\perp$)
Exact Settings
We consider a one-step tabular game, where we have a set of $N$ levels $\theta_1, ..., \theta_N$. Each level $i$ corresponds to a particular initial observation $\tau_i$, such that the same observation may be shared by two different environments. Each level also has an associated reward for each action $a_j, 1 \leq j \leq M$. We model the adversary as a $N$-arm bandit, implemented using tabular Actor-CriticWhen Minimax Regret is Sufficient
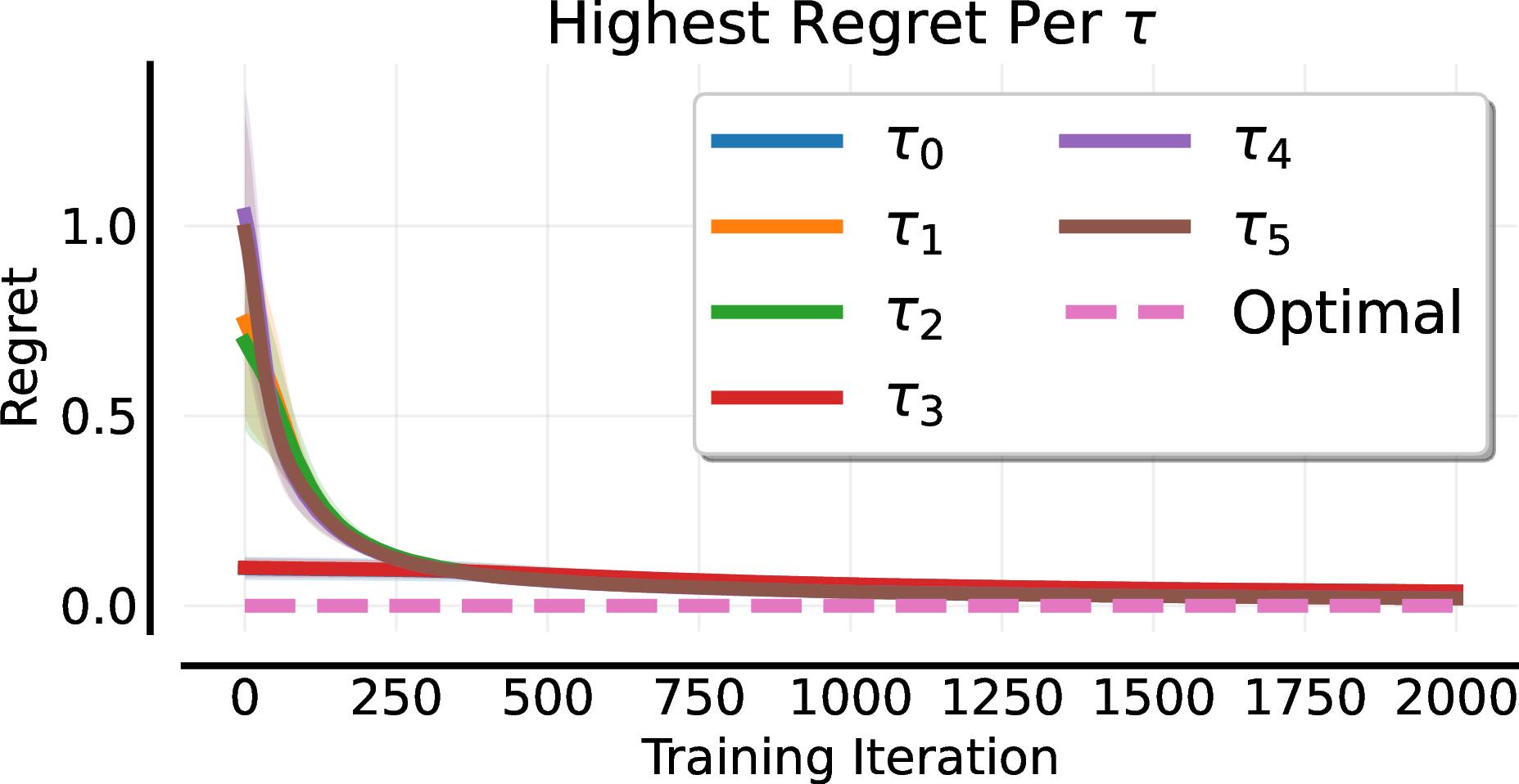
When Minimax Regret Fails
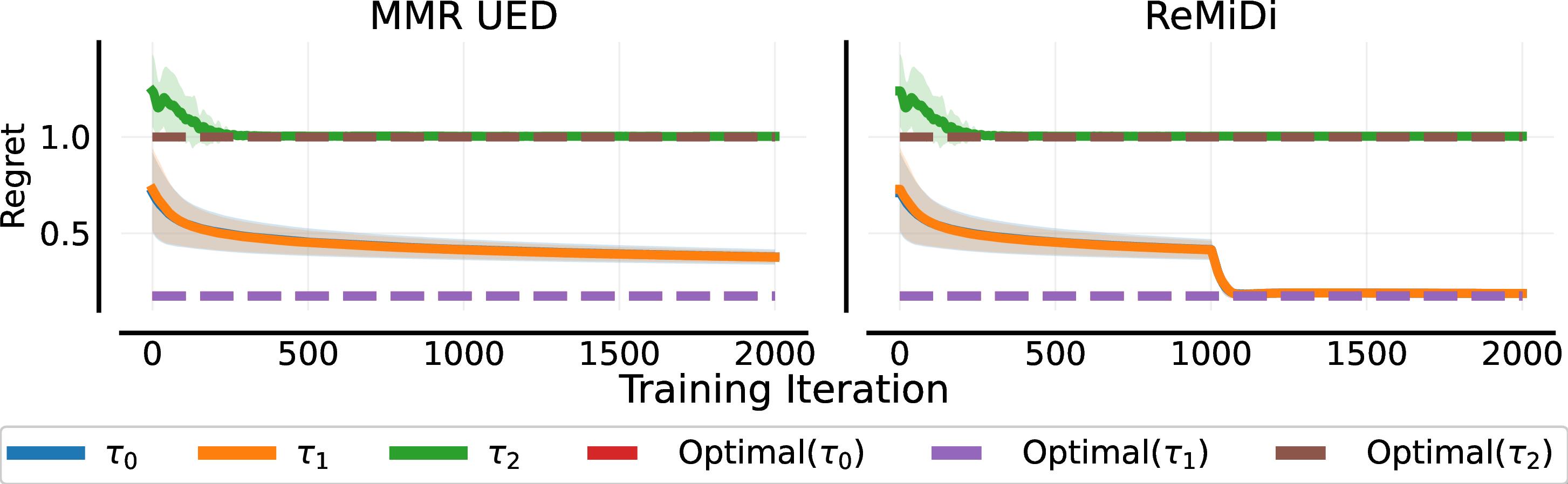
We next examine a UPOMDP where a single policy can no longer be simultaneously optimal over all levels. The setup is the same as the previous experiment, except that $\tau_2 = \tau_1$, $\tau_4 = \tau_3$, etc., meaning that there is some irreducible regret. The figure below shows that regret-based UED rapidly obtains minimax regret, but fails to obtain optimal regret on the non-regret-maximising levels. By contrast, ReMiDi obtains optimal regret on all levels. It does this by first obtaining global minimax regret, at which point it restricts its search over levels to those that are distinguishable from minimax regret levels. Since the agent's policy is not updated on these prior states, it does not lose MMR guarantees.
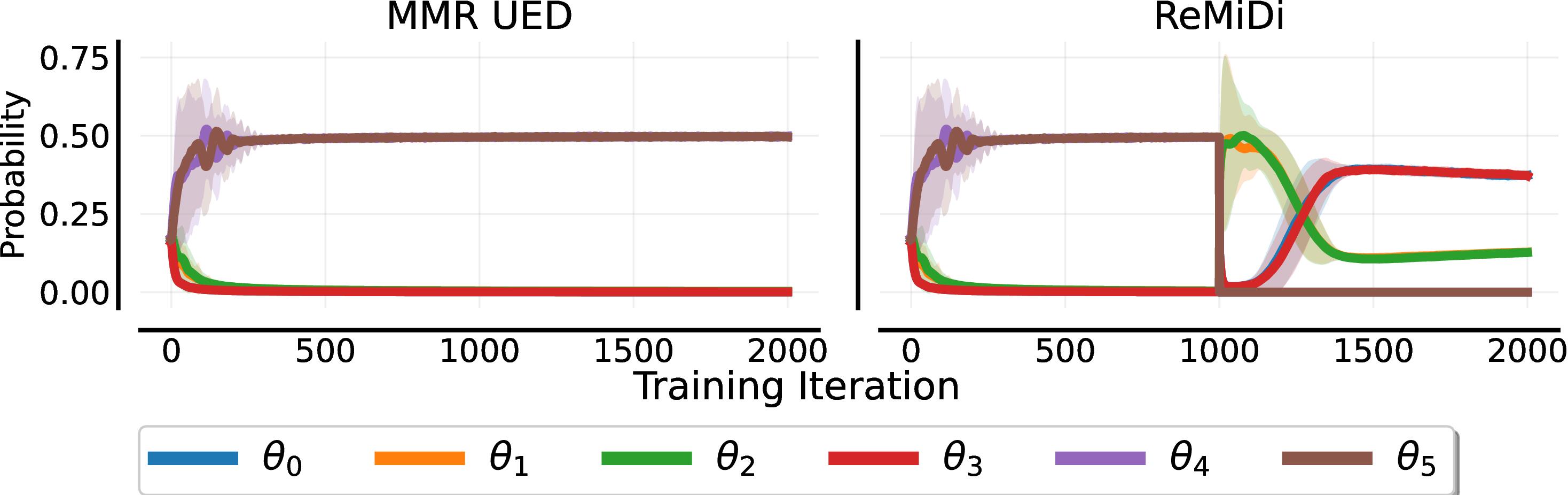
We analyse this further by plotting the probability of each level being sampled over time. Regret-based UED rapidly converges to sampling only the highest-regret levels ($\theta_4$ and $\theta_5$), and shifts the probability of sampling the other levels to zero. By contrast, our multi-step process first samples these high-regret levels exclusively. Thereafter, these are removed from the adversary's options and it places support on all other levels.
This shows that, while we could improve the performance of regret-based UED by adding stronger entropy regularisation
T-Maze & Blindfold
We next consider the T-Maze example discussed earlier. Here the adversary can sample T-mazes or normal mazes. The reward of T-mazes is $+1$ or $-1$ depending on whether the agent reaches the goal or not, and the standard maze reward is the same as is used in prior work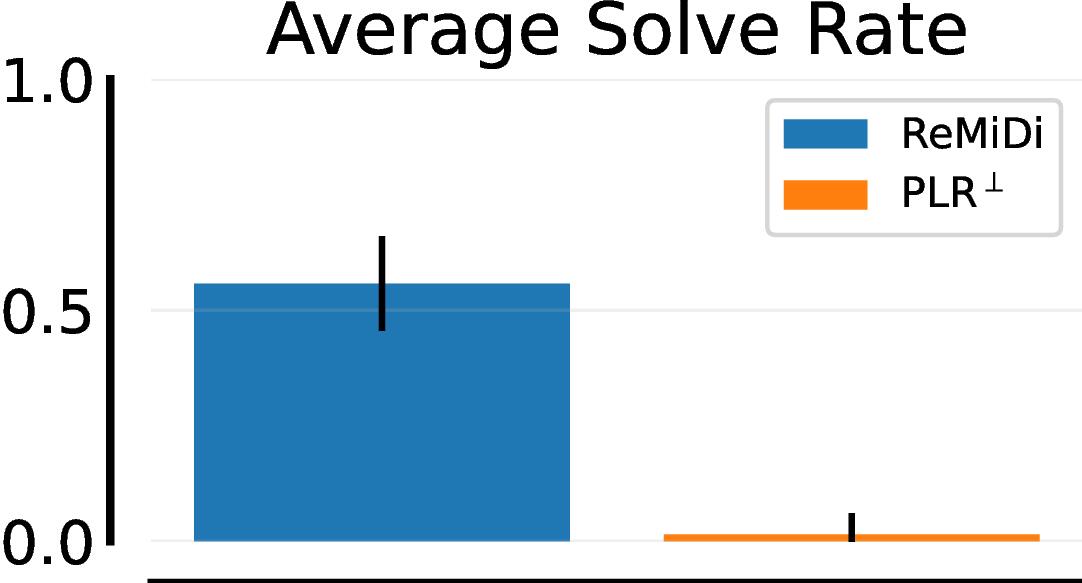
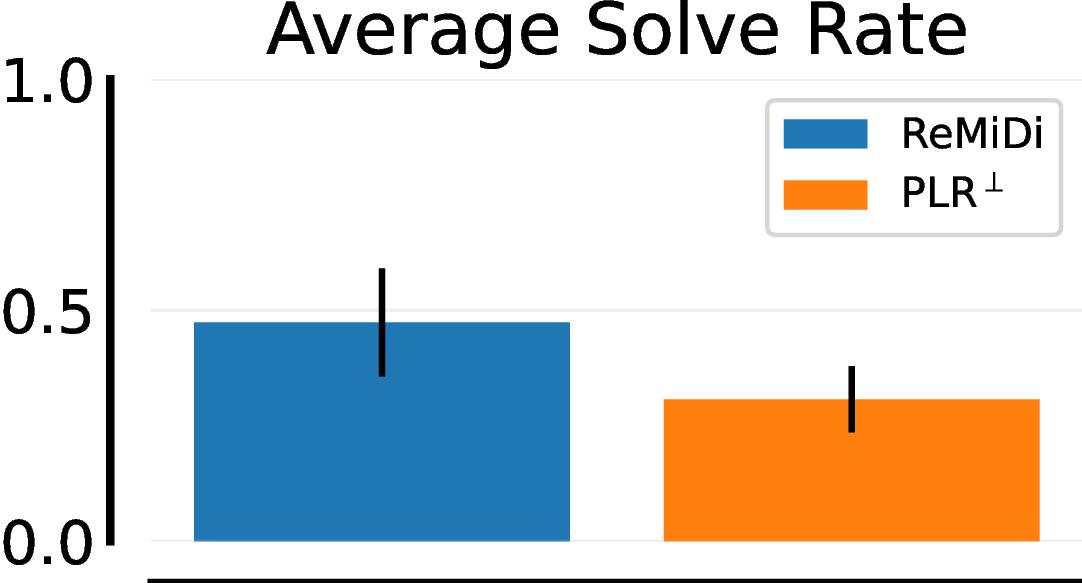
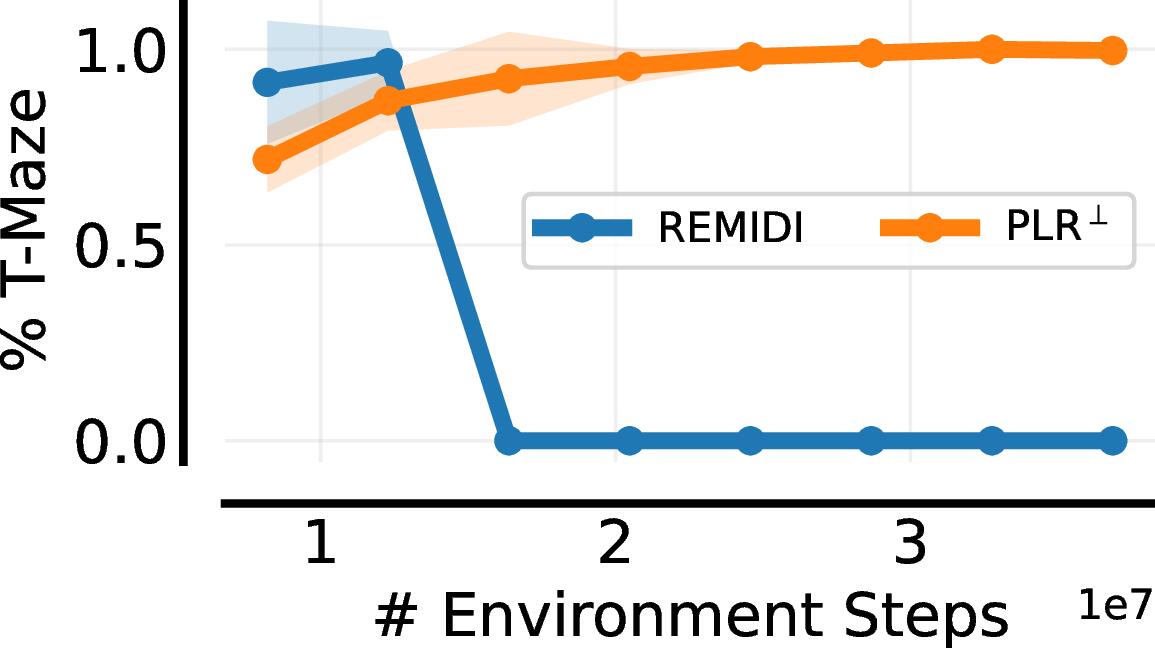
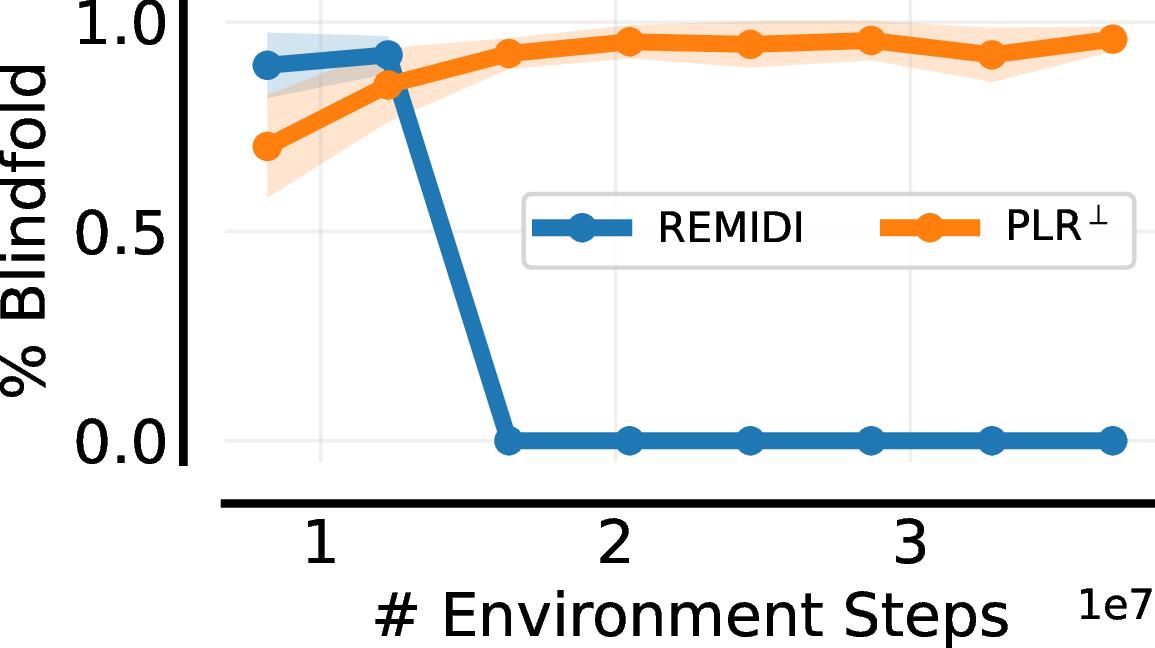
Lever Game
In this environment, inspired by
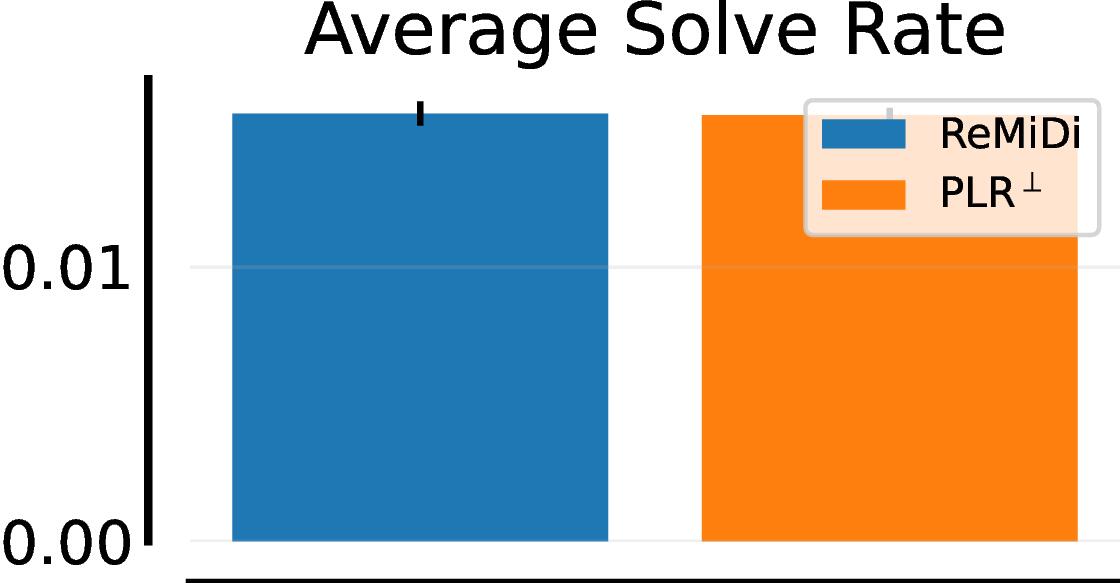
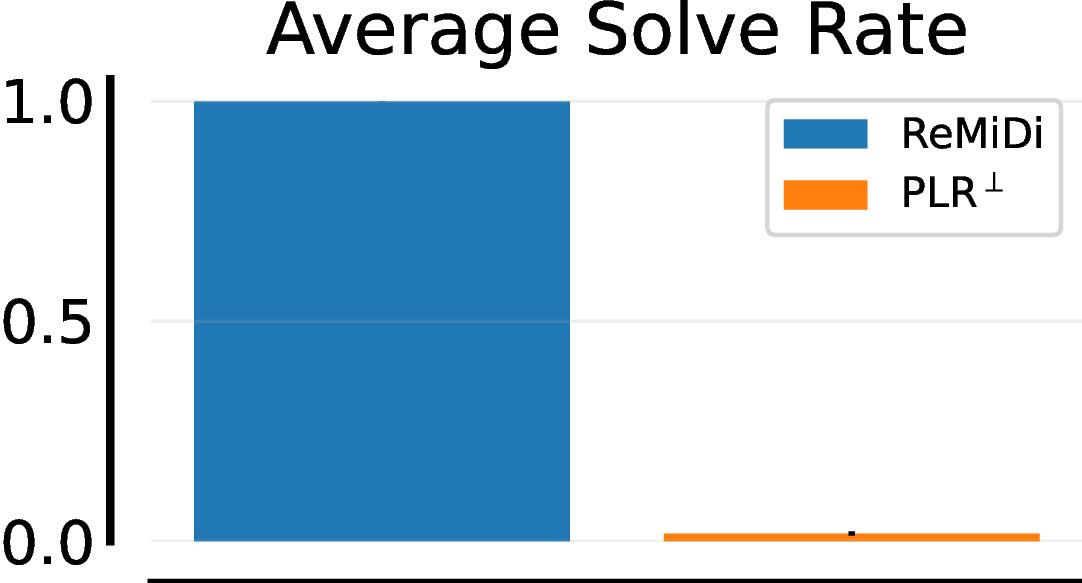
Summary
In summary, we show that minimax regret has a notable failure case when there are environments with high irreducible regret. Our solution concept can address this problem, and ReMiDi results in higher empirical performance in cases like these. We would like to highlight that, in the same way that minimax regret fixes minimax's problem with unsolvable environments, our solution concept can also fix minimax regret's problem with irreducible regret.| Objective | If there are Unsolvable Levels | If there are Irreducible Regret Levels |
|---|---|---|
| Minimax | ❌ | ❌ |
| Minimax Regret | ✅ | ❌ |
| BLP | ✅ | ✅ |
Conclusions / Takeaways
In conclusion, we went over the following core concepts:
- Regret does not always correspond to learnability, even though in practice high-regret levels are often useful for learning
- In cases such as these, minimax regret suffers from the Regret Stagnation problem, manifesting as the adversary sampling primarily levels that provide no learning (e.g., blindfold levels or T-Mazes).
- This may cause our agent to, unnecessarily, perform poorly on a large subset of levels, which we'd like to avoid if possible.
- Our novel solution concept, called the Bayesian Level Perfect Minimax Regret Policy, is a refinement of minimax regret, and addresses this problem.
- We implement a proof-of-concept algorithm, ReMiDi, that empirically addresses this problem.
What now? If you are interested, have a look at our paper for more details and proofs. Our code is also publicly available here. Finally, if you are interested in UED research, have a look at Minimax or JaxUED, two Jax-based UED libraries.