Overview
We present JaxMARL, a library of multi-agent reinforcement learning (MARL) environments and algorithms based on end-to-end GPU acceleration that achieves up to 12500x speedups. The environments in JaxMARL span cooperative, competitive, and mixed games; discrete and continuous state and action spaces; and zero-shot and CTDE settings. We specifically include implementations of the Hanabi Learning Environment, Overcooked, Multi-Agent Brax, MPE, Switch Riddle, Coin Game, and Spatial-Temporal Representations of Matrix Games (STORM). Because of JAX's hardware acceleration, our per-run training pipeline is 12500x faster than existing approaches. We also introduce SMAX, a vectorised version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. By significantly speeding up training, JaxMARL enables new research into areas such as multi-agent meta-learning, as well as significantly easing and improving evaluation in MARL. Try it out here: https://github.com/flairox/jaxmarl!
What is JAX?
JAX is a Python library that enables programmers to use a simple numpy-like interface to easily run programs on accelerators. Recently, doing end-to-end single-agent RL on the accelerator using JAX has shown incredible benefits. To understand the reasons for such massive speed-ups in depth, we recommend reading the PureJaxRL blog post and repository.
JaxMARL Environments


Environments and Benchmarks
We present visualisations of our provided JAX-based environment suites above. To get an idea of the speed-ups provided by our library, we provide benchmarks for the environments in JaxMARL below.
Details on Environments
In this section, we describe each of the environments in JaxMARL. This includes two new environments: STORM and SMAX. STORM is inspired by the Melting Pot environment suite and SMAX is inspired by the StarCraft Multi-Agent Challenge (SMAC).
The StarCraft Multi-Agent Challenge (SMAC) is a popular benchmark but has a number of shortcomings. First, as noted and addressed in SMACv2, SMAC is not particularly stochastic. This means that non-trivial win-rates are possible on many SMAC maps by conditioning a policy only on the timestep and agent ID. Additionally, SMAC relies on StarCraft II as a simulator. While this allows SMAC to use the wide range of units, objects and terrain available in StarCraft II, running an entire instance of StarCraft II is slow and memory intensive. StarCraft II runs on the CPU and therefore SMAC's parallelisation is severely limited with typical academic compute.
Using the StarCraft II game engine also constrains environment design. For example, StarCraft II groups units into three races and does not allow units of different races on the same team, limiting the variety of scenarios that can be generated. Secondly, SMAC does not support a competitive self-play setting without significant engineering work. The purpose of SMAX is to address these limitations. It provides access to a simplified SMAC-like, hardware-accelerated, customisable environment that supports self-play and custom unit types. SMAX models units as discs in a continuous 2D space.
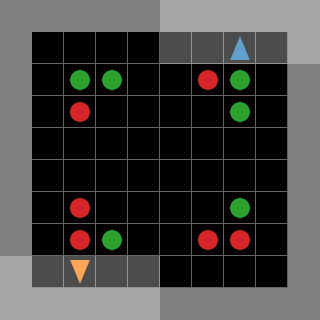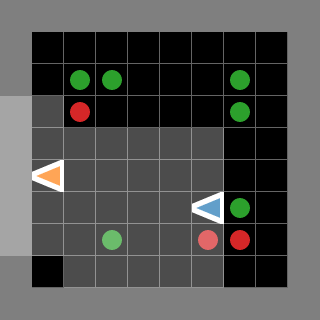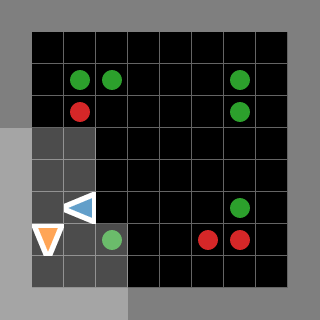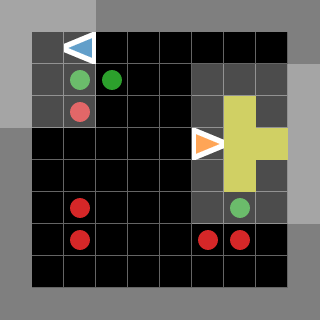
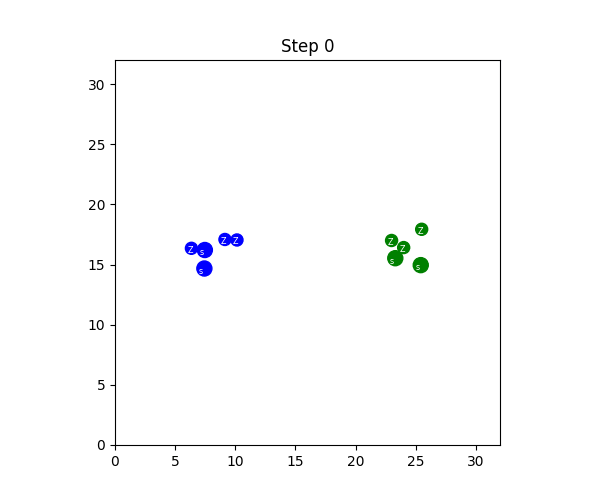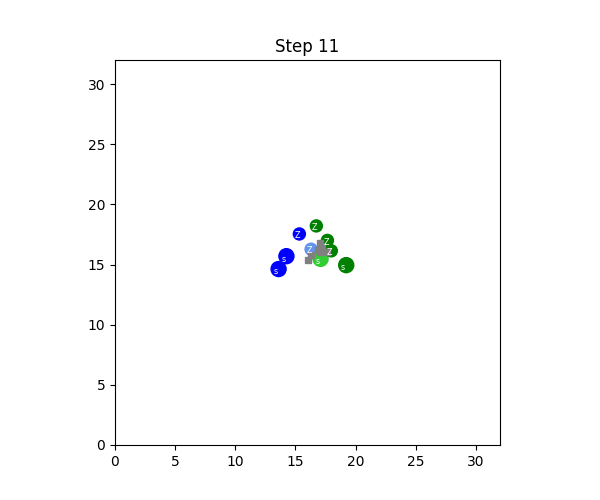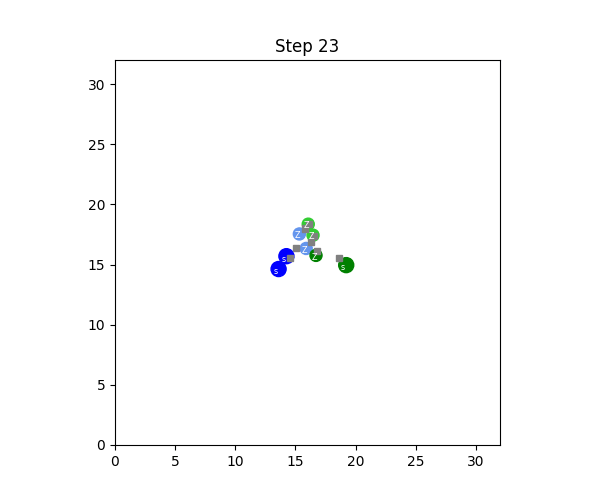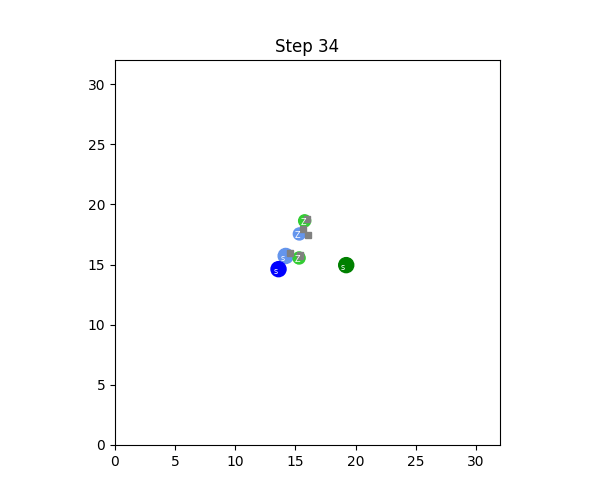
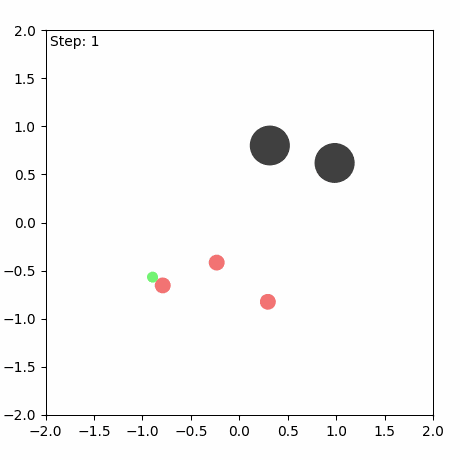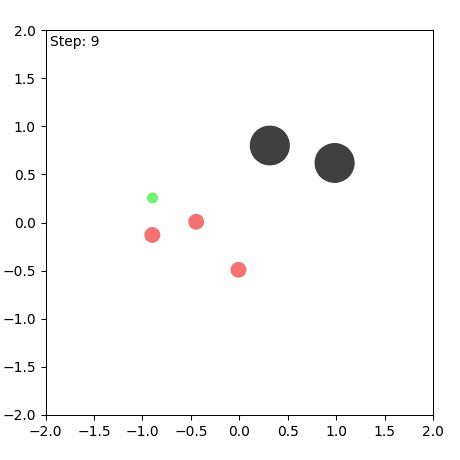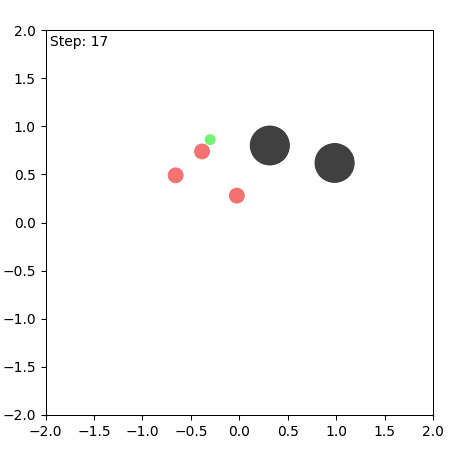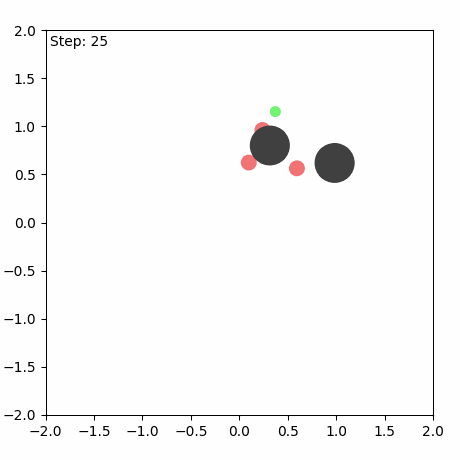
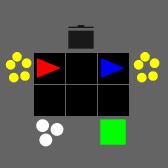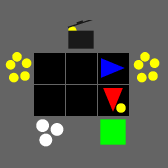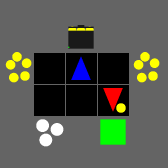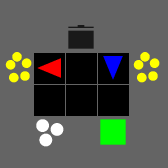
SMAX also features a different, and more sophisticated, heuristic AI. The heuristic in SMAC simply moves to a fixed location, attacking any enemies it encounters along the way, and the heuristic in SMACv2 globally pursues the nearest agent. Thus the SMAC AI often does not aggressively pursue enemies that run away, and cannot generalise to the SMACv2 start positions, whereas the SMACv2 heuristic AI conditions on global information and is exploitable because of its tendency to flip-flop between two similarly close enemies. SMAC's heuristic AI must be coded in the map editor, which does not provide a simple coding interface. The diagram below illustrates these disadvantages.
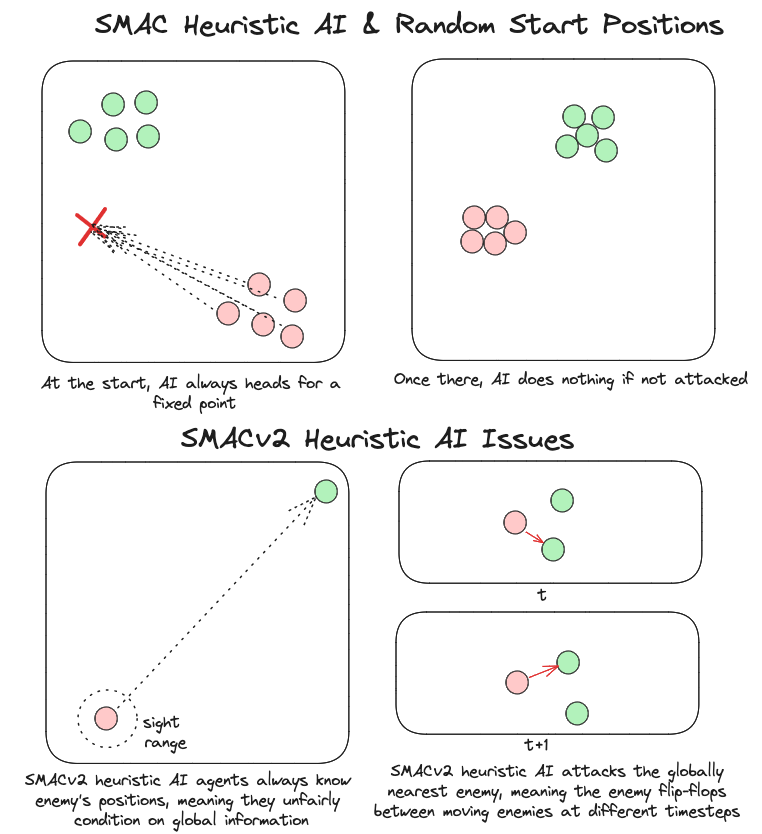
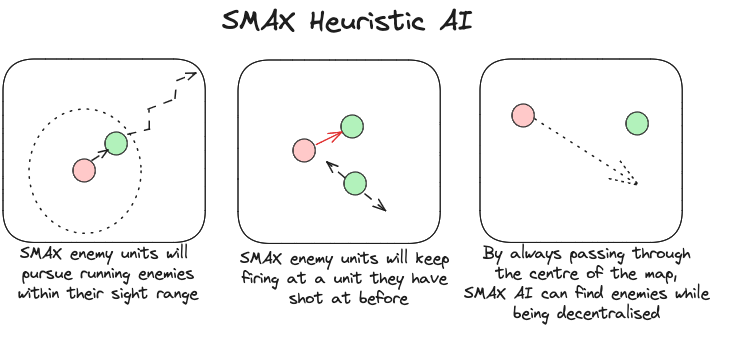
In contrast, SMAX features a decentralised heuristic AI that can effectively find enemies without requiring the global information of the SMACv2 heuristic. This guarantees that in principle a 50% win rate is always achievable by copying the decentralised heuristic policy exactly. This means any win-rate below 50% represents a concrete failure to learn. Some of the capabilities of the SMAX heuristic AI are illustrated in the Figure below.
SMAX scenarios incorporate both a number of the original scenarios from SMAC and scenarios similar to those found in SMACv2. The latter sample units uniformly across all SMAX unit types (stalker, zealot, hydralisk, zergling, marine, marauder) and ensure fairness by having identical team composition for the enemy and ally teams. The details of the scenarios are given in the Table below.
| Scenario | Ally Units | Enemy Units | Start Positions |
|---|---|---|---|
| 2s3z | 2 stalkers and 3 zealots | 2 stalkers and 3 zealots | Fixed |
| 3s5z | 3 stalkers and 5 zealots | 3 stalkers and 5 zealots | Fixed |
| 5m_vs_6m | 5 marines | 6 marines | Fixed |
| 10m_vs_11m | 10 marines | 11 marines | Fixed |
| 27m_vs_30m | 27 marines | 30 marines | Fixed |
| 3s5z_vs_3s6z | 3 stalkers and 5 zealots | 3 stalkers and 6 zealots | Fixed |
| 3s_vs_5z | 3 stalkers | 5 zealots | Fixed |
| 6h_vs_8z | 6 hydralisks | 8 zealots | Fixed |
| smacv2_5_units | 5 uniformly randomly chosen | 5 uniformly randomly chosen | SMACv2-style |
| smacv2_10_units | 10 uniformly randomly chosen | 10 uniformly randomly chosen | SMACv2-style |
| smacv2_20_units | 20 uniformly randomly chosen | 20 uniformly randomly chosen | SMACv2-style |
Spatial-Temporal Representations of Matrix Games (STORM) is inspired by the "in the Matrix" games in Melting Pot 2.0. The STORM environment expands on matrix games by representing them as grid-world scenarios. Agents collect resources which define their strategy during interactions and are rewarded based on a pre-specified payoff matrix.
This allows for the embedding of fully cooperative, competitive or general-sum games, such as the prisoner's dilemma. Thus, STORM can be used for studying paradigms such as opponent shaping, where agents act with the intent to change other agents' learning dynamics, which has been empirically shown to lead to more prosocial outcomes.
Compared to the Coin Game or matrix games, the grid-world setting presents a variety of new challenges such as partial observability, multi-step agent interactions, temporally-extended actions, and longer time horizons. Unlike the "in the Matrix" games from Melting Pot, STORM features stochasticity, increasing the difficulty.
Multi-Agent Particle Environments (MPE)
The multi-agent particle environments feature a 2D world with simple physics where particle agents can move, communicate, and interact with fixed landmarks. Each specific environment varies the format of the world and the agents' abilities, creating a diverse set of tasks that include both competitive and cooperative settings. We implement all the MPE scenarios featured in the PettingZoo library and the transitions of our implementation map exactly to theirs.
We additionally include a fully cooperative predator-prey variant of simple tag, which first appeared in FACMAC. The code is structured to allow for straightforward extensions, enabling further tasks to be added.
Inspired by the popular videogame of the same name, Overcooked is commonly used for assessing fully cooperative and fully observable Human-AI task performance. The aim is to quickly prepare and deliver soup, which involves putting three onions in a pot, cooking the soup, and serving it into bowls. Two agents, or cooks, must coordinate to effectively divide the tasks to maximise their common reward signal. Our implementation mimics the original from Overcooked-AI, including all five original layouts and a simple method for creating additional ones.
Hanabi is a fully cooperative partially observable multiplayer card game, where players can observe other players' cards but not their own. To win, the team must play a series of cards in a specific order while sharing only a limited amount of information between players. As reasoning about the beliefs and intentions of other agents is central to performance, it is a common benchmark for ZSC and ad-hoc teamplay research.
Our implementation is inspired by the Hanabi Learning Environment and includes custom configurations for varying game settings, such as the number of colours/ranks, number of players, and number of hint tokens. Compared to the Hanabi Learning Environment, which is written in C++ and split over dozens of files, our implementation is a single easy-to-read Python file, which simplifies interfacing with the library and running experiments.
MABrax is a derivative of Multi-Agent MuJoCo, an extension of the MuJoCo Gym environment, that is commonly used for benchmarking continuous multi-agent robotic control. Our implementation utilises Brax as the underlying physics engine and includes five of Multi-Agent MuJoCo's multi-agent factorisation tasks, where each agent controls a subset of the joints and only observes the local state. The included tasks are: ant_4x2, halfcheetah_6x1, hopper_3x1, humanoid_9|8, and walker2d_2x3. The task descriptions mirror those from Gymnasium-Robotics.
Originally used to illustrate the Differentiable Inter-Agent Learning algorithm, Switch Riddle is a simple cooperative communication environment that we include as a debugging tool.
N prisoners held by a warden can secure their release by collectively ensuring that each has passed through a room with a light bulb and a switch. Each day, a prisoner is chosen at random to enter this room. They have three choices: do nothing, signal to the next prisoner by toggling the light, or inform the warden they think all prisoners have been in the room.
The game ends when a prisoner informs the warden or the maximum time steps are reached. The rewards are +1 if the prisoner informs the warden, and all prisoners have been in the room, -1 if the prisoner informs the warden before all prisoners have taken their turn, and 0 otherwise, including when the maximum time steps are reached. We benchmark using the implementation from MARCO.
Coin Game is a two-player grid-world environment which emulates social dilemmas such as the iterated prisoner's dilemma. Used as a benchmark for the general-sum setting, it expands on simpler social dilemmas by adding a high-dimensional state. It is commonly used to study opponent shaping in works such as Learning with Opponent-Learning Awareness and its following works.
Two players, `red' and `blue' move in a grid world and are each awarded 1 point for collecting any coin. However, `red' loses 2 points if `blue' collects a red coin and vice versa. Thus, if both agents ignore colour when collecting coins their expected reward is 0.
Algorithms
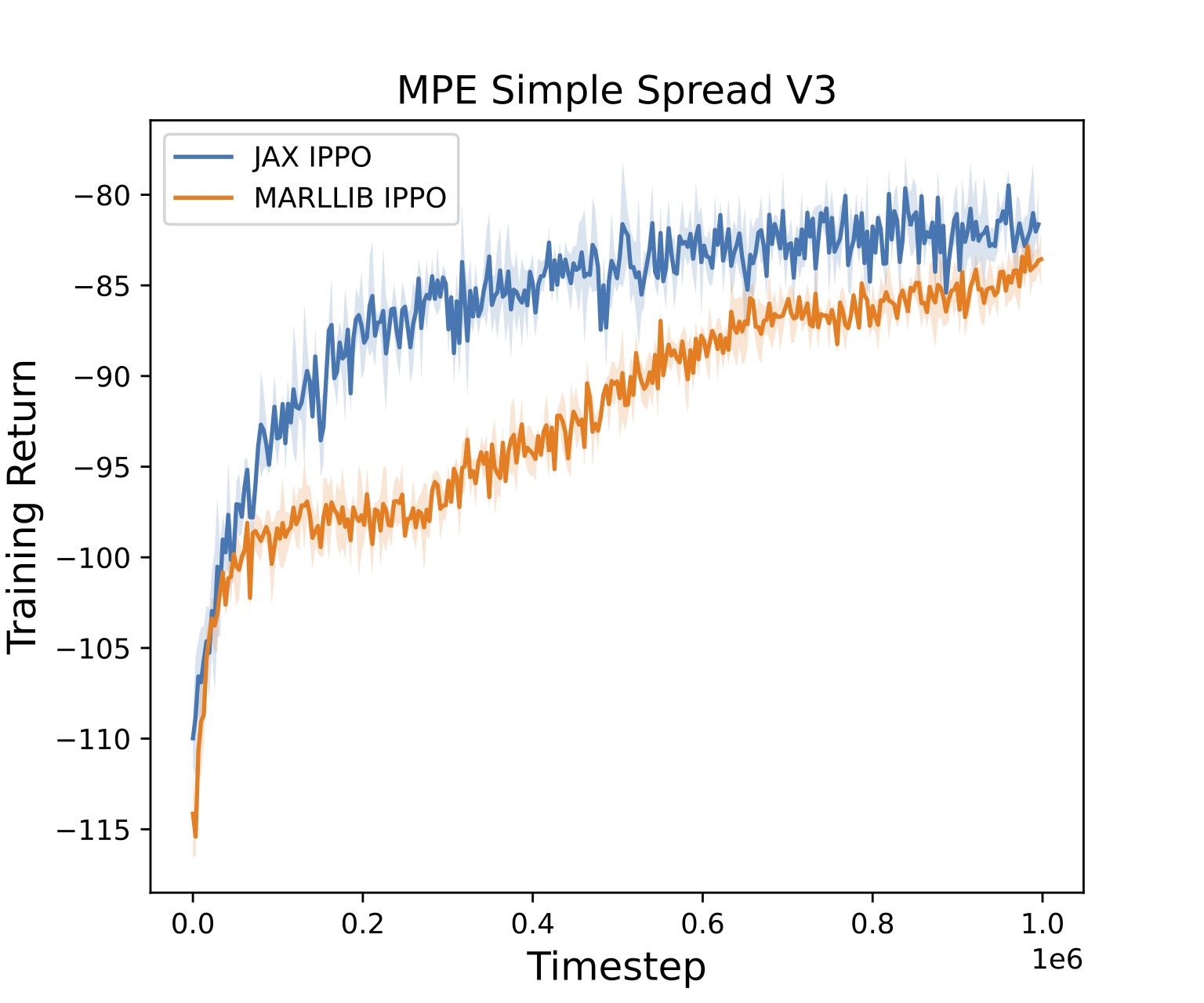
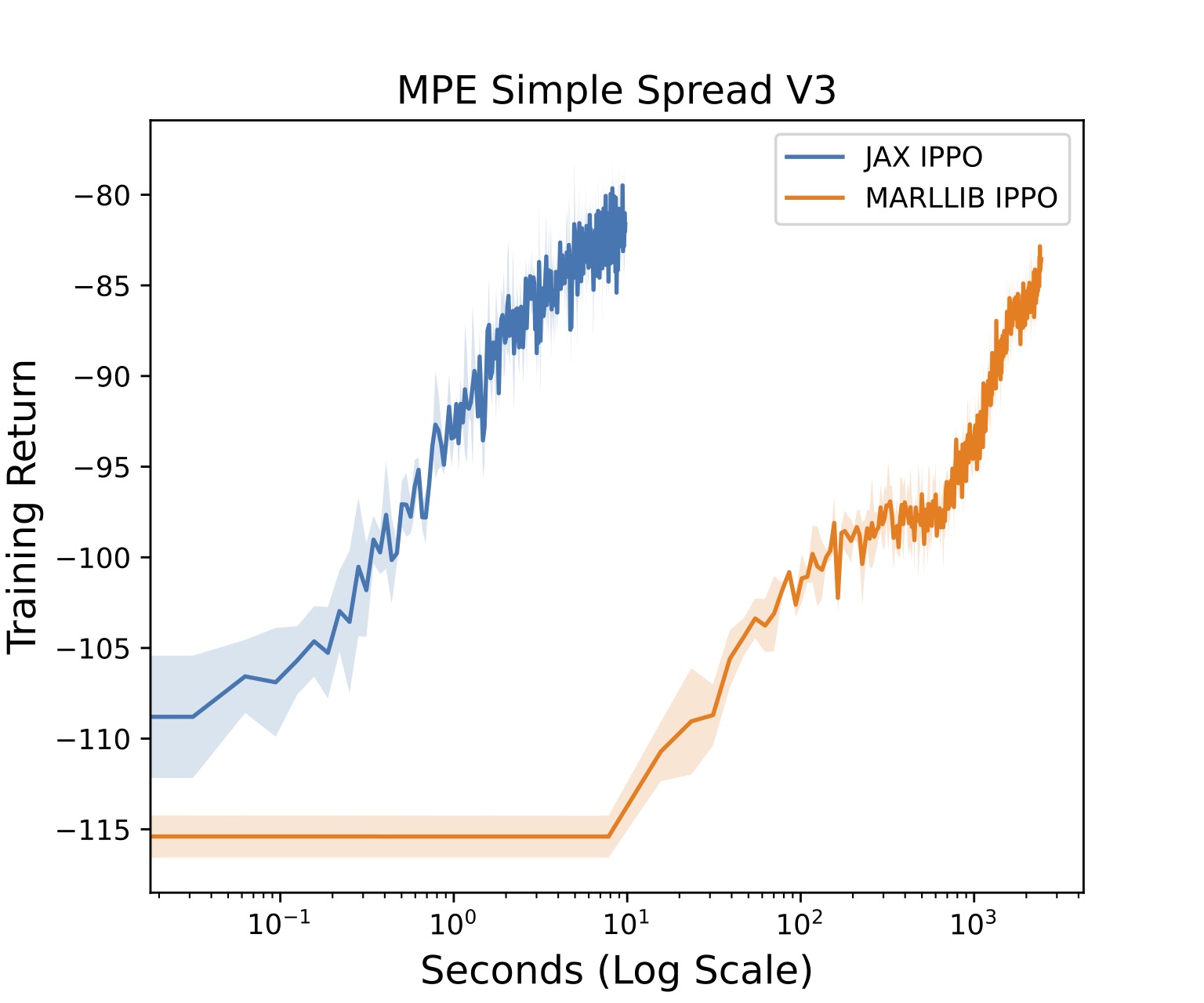
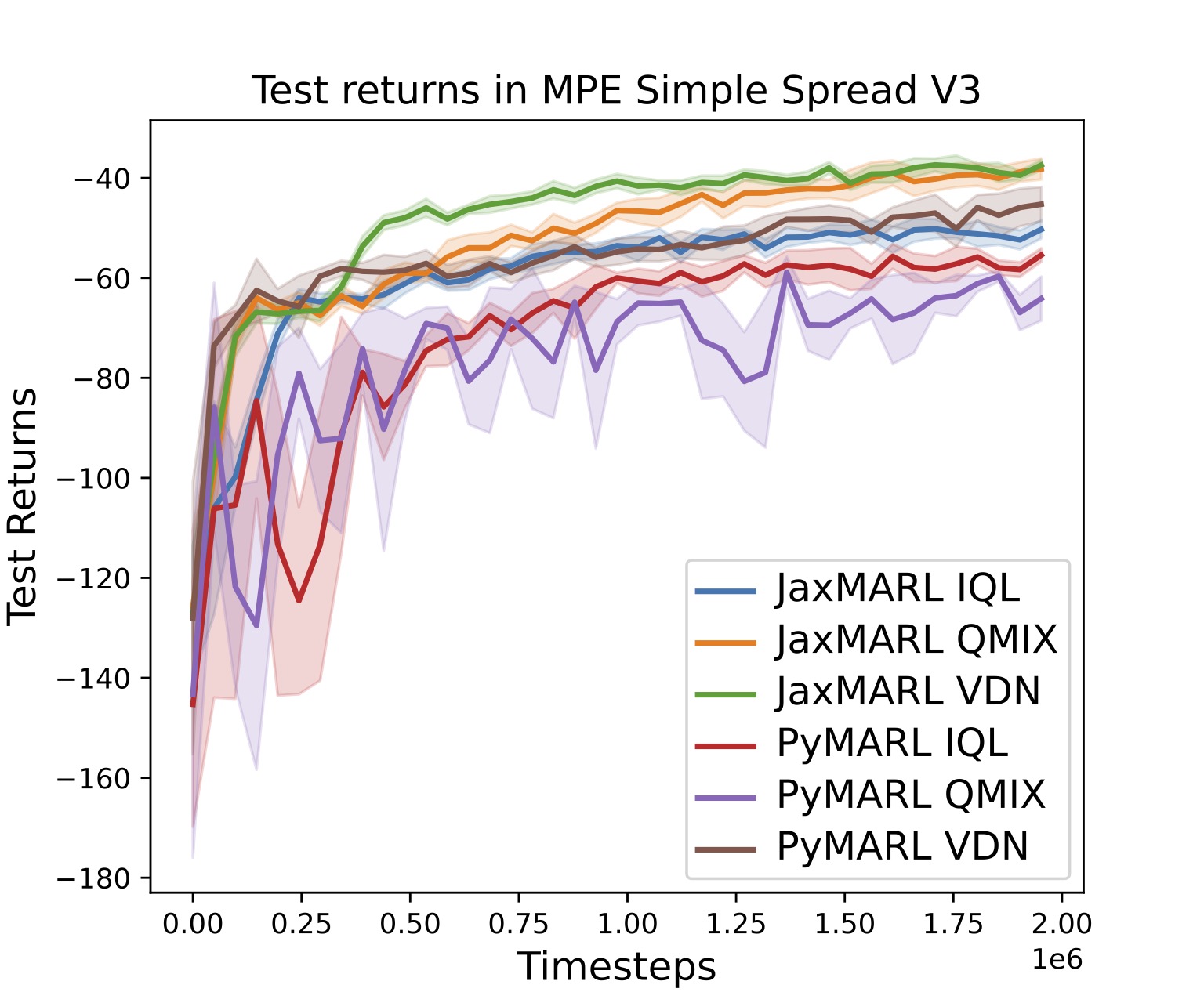
We provide an Independent PPO (IPPO) implementation and include results on these environments. Here's a simple colab notebook you can run to test this out here. For training on MPE Spread, we compare directly to the popular MARLLIB IPPO implementation. JaxMARL achieves very similar results while running over 100x faster, as seen in the Figure below!
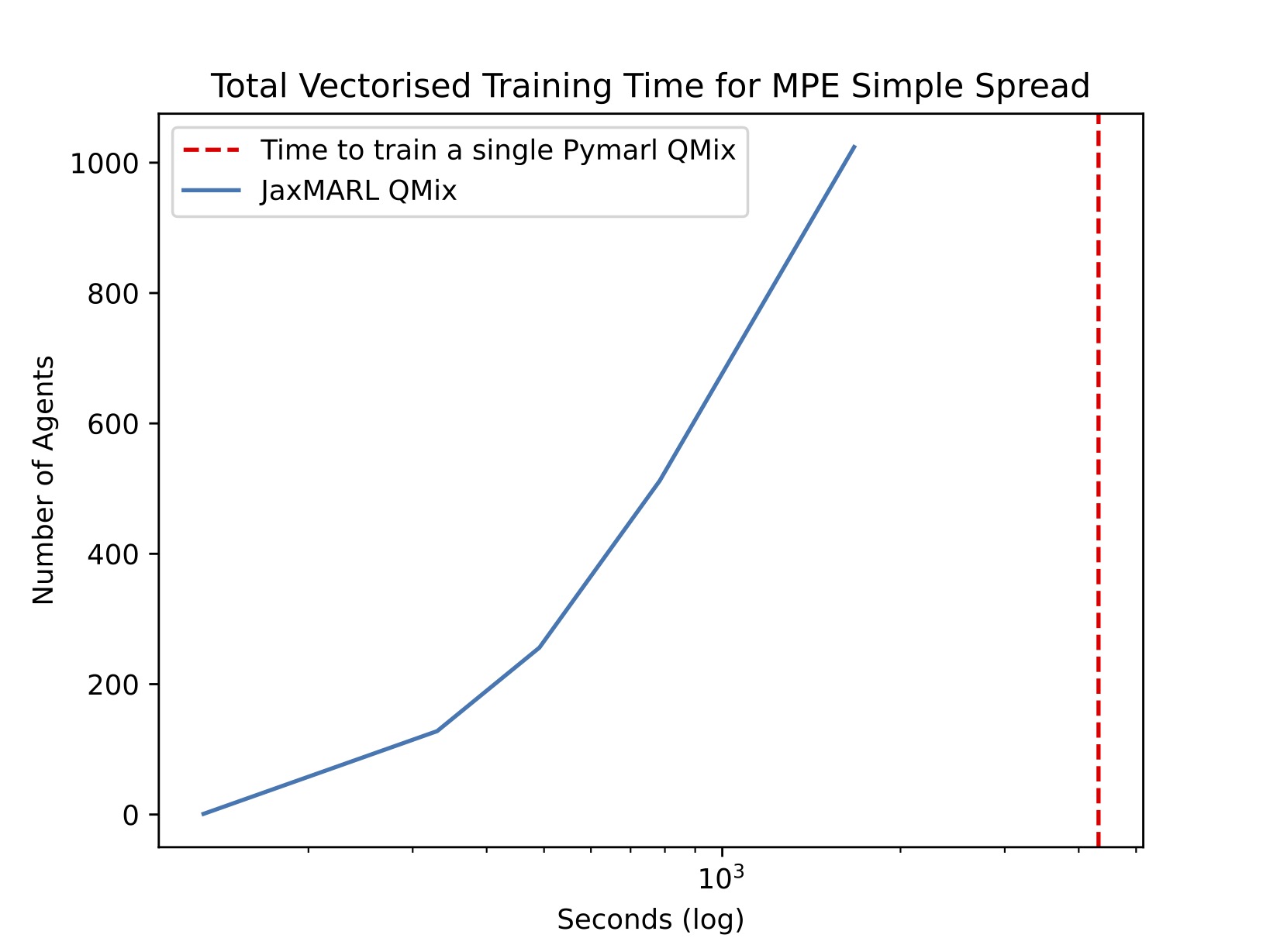
By just adding a few lines of code, we then vmap the entire IPPO algorithm. This allows us to train many independent runs in parallel on a single GPU. We show the speeds in the figure below. This is extremely useful for collecting a statistically significant number of seeds, hyperparameter tuning, and meta-evolution!
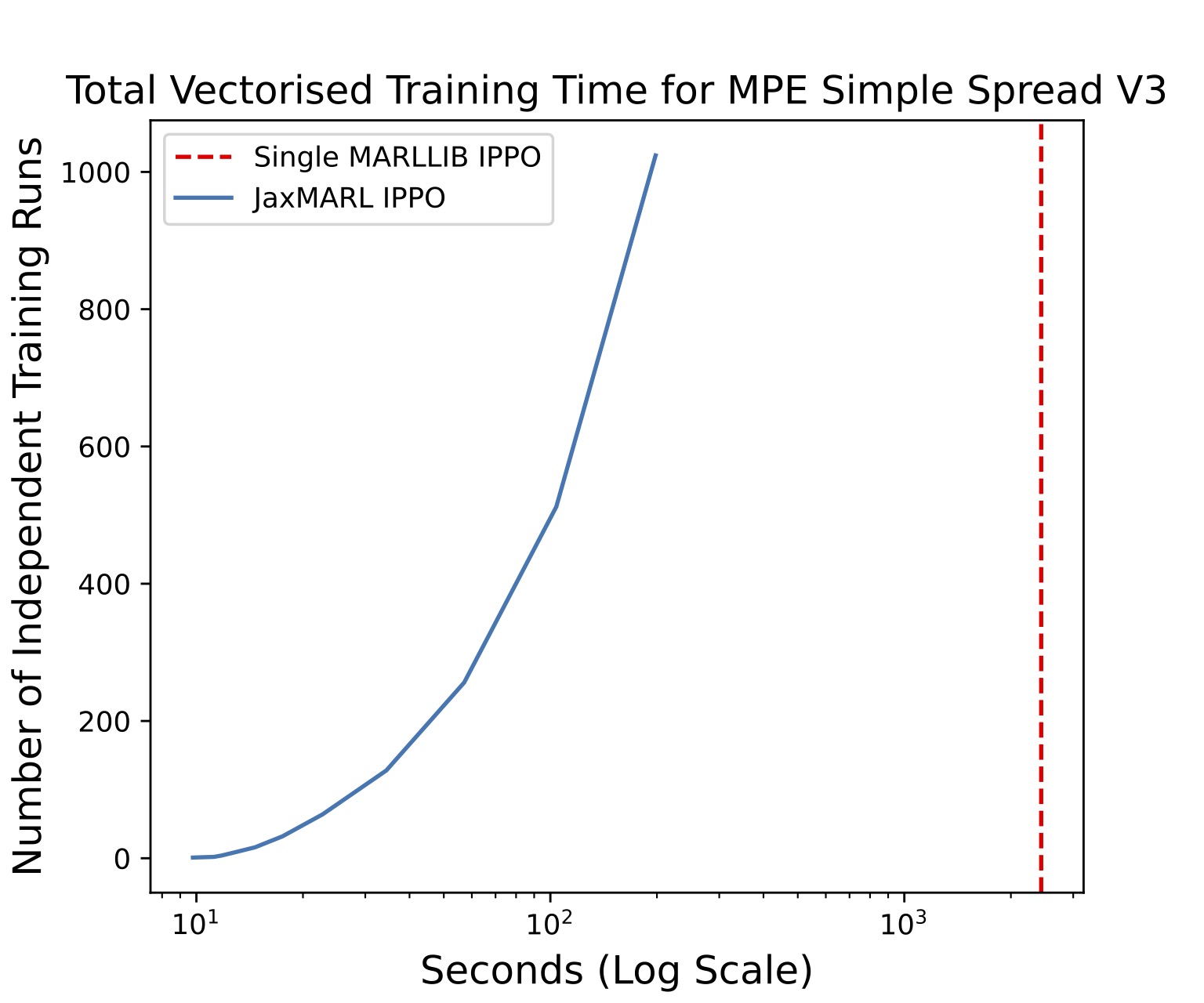
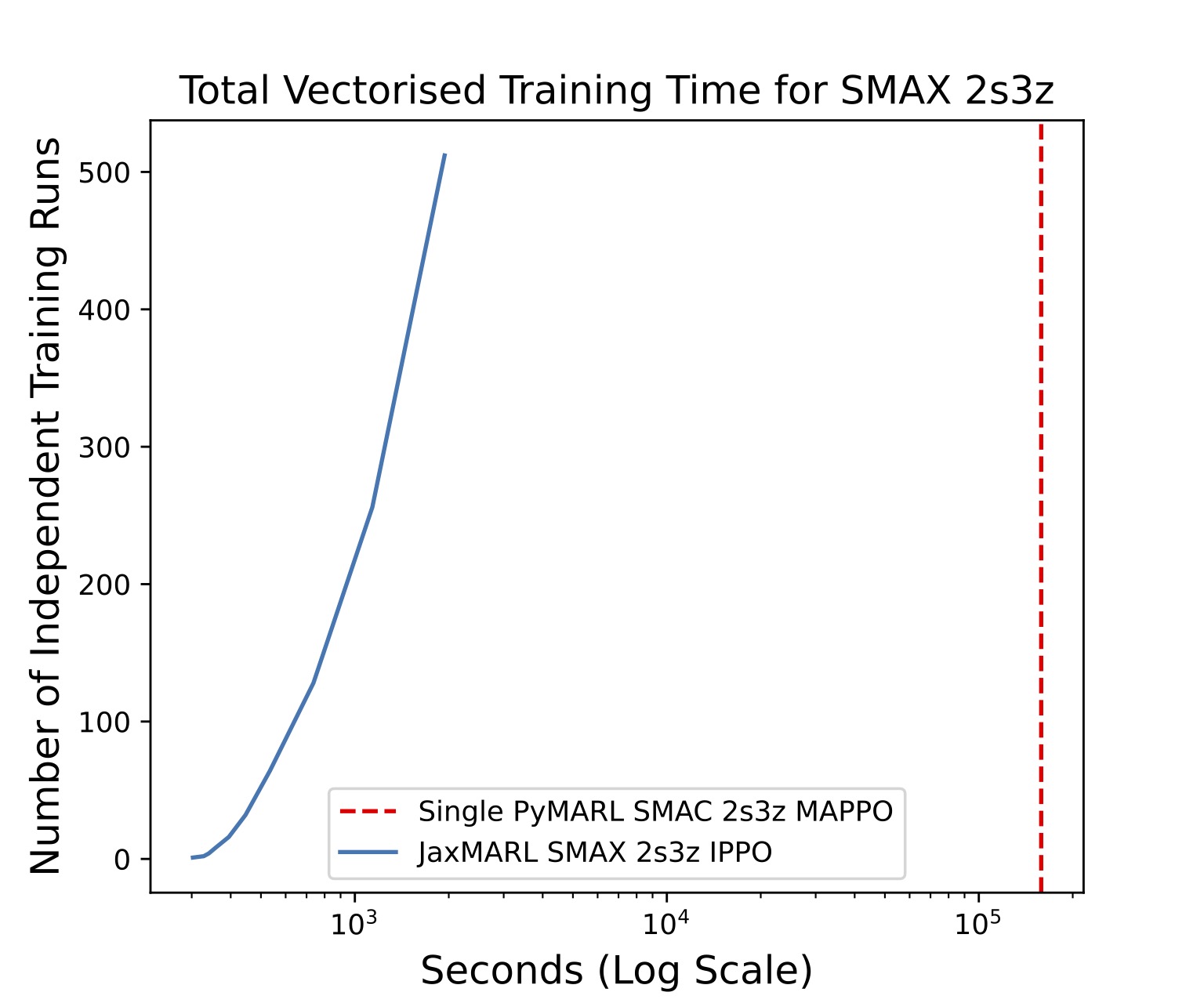
In MPE Spread, we run 1024 training runs in almost 10x less time than it takes to run a single training run using MARLLIB! That's a 10000x speedup! Furthermore, we perform the same experiment on SMAX and find that we can train 512 runs in SMAX's 2sz in almost 100x less time than it takes to run a single training run using PyMARL.
Furthermore, we include several other popular algorithms in JaxMARL, including QMIX, VDN, and MAPPO.
Conclusion
We introduced JaxMARL, a pure JAX-based library of multi-agent reinforcement learning (MARL) environments and algorithms. We show that we achieve massive speed-ups in MARL training, enabling faster iteration speeds and hyperparameter tuning while also lowering the computational barrier to entry for MARL.
We highly recommend reading the associated paper to get a more in-depth explanation of the library and to try the repo out for yourself!
For more ideas of what you can do with JaxMARL, we recommend checking out the PureJaxRL blog post!
Related Works
This works is heavily related to and builds on many other works. We would like to highlight some of the works that we believe would be relevant to readers.